Высоконагруженные приложения
Предисловие
DIA(data-intensive application)Высоконагруженные данными приложения. Узким местом является количество, скорость поступления или сложность данных.
CIA(compute-intensive application)Высоконагруженные вычислениями приложения. Узким местом является CPU.
I. Основы информационных систем
1. Надежные, масштабируемые и удобные в сопровождении приложения
Надёжность
Проблемы с надежностью можно верхнеуровнево разделить на три категории.
- Аппаратные сбои. В современном мире обычно решаются многократным резервированием или возможностью быстро масштабироваться.
- Программные то сбои. Код не совершенен, баги могут всплывать где угодно. Решается грамотной архитектурой, тестированием и многими другими подходами.
- Человеческий фактор. Люди допускают ошибки и это неизбежно.
Масштабируемость
- Автор пишет, что Масштабируемость - это способность системы справляться с возросшей нагрузкой. Мне кажется, что в современном мире способность системы масштабироваться вниз не менее важна.
- Важно выбрать корректные параметры нагрузки на которые будем опираться при анализе проблемы масштабирования. Это может быть экстремумы или наоборот низкие процентили.
- Описание производительности. После того как описали нагрузку важно выяснить, что конкретно произойдёт при ее возрастании.
Удобство сопровождения
Можно выделить три основных принципа разработки ПО облегчающих его сопровождение.
- Удобство эксплуатации. Облегчает обслуживающему персоналу поддержание беспрепятственной работы системы.
- В самом коде сервиса могут быть заложены компоненты облегчающие его эксплуатацию. Например встроенный мониторинг, масштабируемость между узлами, внятная документация и так далее.
- Простота. Облегчает понимание системы новыми инженерами путем максимально возможного ее упрощения.
- Упрощение системы не обязательно означает сокращение ее функциональности. Оно может означать также исключение побочной сложности. Сложность можно понимать как побочную если она возникает вследствие конкретной реализации, а не является неотъемлемой частью решаемой задачи (с точки зрения пользователей).
- Абстракция - хороший и наверное главный инструмент сохранения простоты. Примером такой абстракции может являться SQL скрывающий сложность хранения и структур данных. Или язык программирования высокого уровня скрывающий сложности работы.
- Возможность развития. Упрощает разработчикам внесение в будущем изменений в систему, адаптацию ее для непредвиденных сценариев использования при смене требований. Известна под названиями «расширяемость» (extensibility), «модифицируемость» (modifiability) и «пластичность» (plasticity).
2. Модели данных и языки запросов
- Модели данных вложены друг в друга как матрешка и описывают по сути разные уровни абстракций.
- Например мы можем описать модель данных на уровне бизнес элементов и API, что представляют доступ как ним. На следующем уровне это будет уже модель сериализации, дальше модель хранения. Так можно абстрагироваться вплоть до физического хранения на уровне электронов.
Реляционная модель в сравнении с документоориентированной моделью
Объектно-реляционное несоответствие (impedance mismatch)
Расстыковка между реаляционной моделью и абстракциями языка. Необходимо реализовывать переходную логику между таблицами и сущностями языка. Например ORM.
- В главе по верхам описывается сравнение реляционных и документориентированных БД. Основными отличием представляется возможности объединения и связи многие ко многим. В случае РСУБД этим задачи решает оптимизатор запросов, в случае документориентрованных БД код программы.
- Интересная идея. NoSQL это не “schemaless” подход, а скорее “schema-on-read”. Ведь наш код все равно ждет какую-то схему даже если она не валидируется в момент записи.
Языки запросов данных
- Автор сравнивает императивные языки запросов к данным которые были распространенны в прошлом с декларативных.
- К декларативным можно отнести SQL или CSS-селекторы в браузере.
- MapReduce. Короткий обзор фреймворка на примере MongoDB.
- Интересна мысль, что синтаксис aggregated pipeline в MongoDB по факту есть шаг в сторону декларативного похода от классического императивного MapReduce.
Графоподобные модели данных
Графы удобны своими возможностями расширения: по мере добавления в приложение новых свойств можно легко расширить граф с целью учесть изменения в структурах данных приложения.
- Интересным для меня моментом является идея нахождения на одном графе разного рода сущностей.
- Люди и города в которых они проживают.
- Город может быть связан линками со штатами, округами и странами и так далее.
- Хороший пример: на этом же графе аллергия на тот или иной продукт человека.
- Cypher - декларативный язык запросов графовых данных созданный для Neo4j.
- В главе так же был обзор на следующие темы которые не показались мне интересными в настоящий момент. Полагаю они носят сугубо исторический характер:
- Хранилище тройных кортежей и SPARQL.
- Хранилище на базе подхода что данные это
(субъект, предикат, модель). Где субъект это вершина графа, а объект может быть как атрибутом вершины, а может другой вершиной и тогда этот кортеж описывает ребро.
- Хранилище на базе подхода что данные это
- Модель данных RDF. Концепция сохранения в вебе помимо человекочитаемых данных ещё и машиночитаемых, что позволяет построить глобальную БД. Технология толком не взлетела и смысла в ней вроде как нет.
- Язык запросов Datalog. Фундамент для многих других языков но по факту мало используется. После первого прочтения ничего не понял в механизмах его работы.
- Хранилище тройных кортежей и SPARQL.
3. Подсистемы хранения и извлечения данных
Если в прошлой главе разбиралось как положить данные в БД и каким запросом потом их оттуда извлечь то в этой автор планирует обсудить тоже самое с точки зрения БД.
Базовые структуры данных БД
Краткое введение в идею индексов упрощающих поиск необходимых строк а базе.
- Хеш-индексы.
- Простейшая идея индекса. Отлично подходит для БД типа KV.
- Представляет из себя hash-map где K это ключ из БД, а value это например смещение по файлу лога БД.
- SSTable.
- Отсортированный по ключам индекс.
- Рабочий блок индекса находится в оперативной памяти, что делает процедуру вставки дешёвой.
- Даже если требуемый сегмент не в оперативной то за счет сортировки мы как минимум примерно знаем где он.
- Принцип работы.
- Все пишем в сбалансированное дерево в памяти (например красно-черное дерево). Это MemTable.
- Как только MemTable превысит заданный порог записываем новый файл SSTable на диск.
- B-деревья.
- Семейство B-Tree индексов — это наиболее часто используемый тип индексов, организованных как сбалансированное дерево, упорядоченных ключей.
- WAL или redo лог частый вспомогательный инструмент для индексов типа b-tree.
Обработка транзакций или аналитика?
OLTP vs OLAP
OLTP vs OLAP
Обработка транзакций или аналитика?
Два основных паттерна запросов к БД:
OLTP
Online transaction processing. Обработка транзакций в реальном времени.
OLAP
Online analytical processing. Аналитическая обработка данных в реальном времени.
Свойство Системы обработки транзакций (OLTP) Аналитические системы (OLAP) Основной паттерн чтения Небольшое количество записей на один запрос, извлекаются по ключу Агрегирование по большому количеству записей Основной паттерн записи Произвольный доступ, операции записи с низким значением задержки на основе вводимых пользователем данных Групповой импорт (ETL) или поток событий В основном применяется Конченными пользователям/заказчиками, через веб-приложения Штатным аналитиком, для поддержки принятия решения Какие данные отражает Актуальное состояние данных (текущий момент времени) Историю событий, происходивших на протяжении отрезка времени Размер набора данных От гигабайтов до терабайтов От терабайтов до петабайтов Parent:: Высоконагруженные приложения Friend:: Olap Cube
Ссылка на оригинал
Data warehouse
- На предприятии могут одновременно работать десятки разных OLTP БД.
- Администраторы этих систем не охотно представляют доступ к ним аналитикам так как их запросы могут быть весьма дорогими и поднимать большие выборки.
- DW хранилище представляет собой собранные и обработанные данные из всех этих OLTP БД.
- Процесс загрузки этих данных - ETL.
- Алгоритмы индексации из предыдущего раздела хороши для OLTP но существенно хуже подходят для OLAP хранилищ.
- В центре DW может находиться так называемая таблица фактов. Каждая строка это событие (продажа товара, посещение сайта) представляющее собой основную цель сбора DW.
- Большинство столбцов в таких таблицах будут ключами на другие таблицы которые содержат можно назвать таблицами измерений.
- Таблица фактов - событие. Таблицы измерений ответ на вопросы по этому событию - “кто”, “что”, “где”, “когда” и так далее.
- Даже дата и время могут быть сущностью таблицы измерений.
- Эта схема называется “звезда”.
- Если же таблицы измерений в свою очередь ветвятся дальше то такую схему условно можно назвать “снежинка”.
Столбцовое хранилище
- В Data Warehouse часто количество столбцов в таблицах может измеряться сотнями. При этом запросы вида
SELECT * FROM…встречаются крайне редко. При этом могут запрашиваться огромное количество строк. - Идея столбцовых хранилищ проста: нужно хранить рядом значения не из одной строки, а из одного столбца. Если каждый столбец хранится в отдельном файле, то запросу требуется только прочитать и выполнить синтаксический разбор необходимых запросов столбцов, что может сэкономить массу усилий. (с. 128)
- Помимо преимуществ для построения запросов описанных выше столбцовые хранилища, а точнее отдельные столбцы в них отлично подходят для сжатия.
- Например с помощью битовой карты (bitmap encoding).
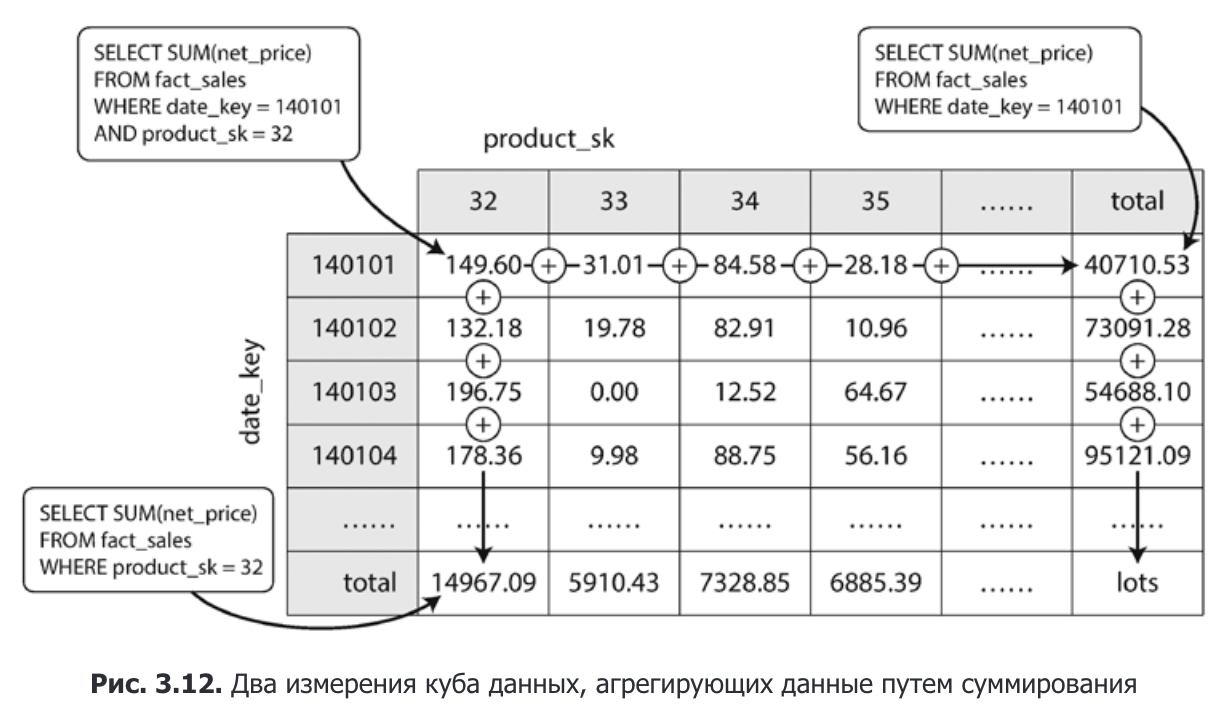
Olap Cube
Olap Cube
- OLAP-куб или куб-данных это материализованное представление где некоторые агрегаты уже посчитаны заранее. Пример:
Parent:: Высоконагруженные приложения
Ссылка на оригинал- OLAP-куб или куб-данных это материализованное представление где некоторые агрегаты уже посчитаны заранее. Пример:
4. Кодирование и эволюция
- Очевидно что с течением времени приложение будет меняться. В том числе будет меняться и представление данных в БД.
- Реляционные БД решают эту задачу через миграции.
- Schemaless БД по идее из коробки способы к эволюции.
- Важной задачей разработки сервиса является поддержка не только обратной но и прямой совместимость. То есть старое приложение должно уметь работать с новыми данными.
Форматы кодирования данных
JSON и XML
- Достаточно обычные мысли про плюсы и минусы. Автор похоже воспринимает подобные форматы как неизбежное зло или компромиcс.
Бинарные форматы
- Интересная идея с бинарной упаковкой JSON в формат MessagePack.
- Формат используется автором просто для демонстрации идеи. Так как выигрыша практически нет. Это бинарное представление хранит даже полностью название полей и выигрыш минимальный. (с. 149)
ThriftиProtobufне имеют существенных отличий в описании. Схема, теги полей и бинарное представление отличающееся лишь реализацией.Apache Avroинтересен тем, что позволяет не кодировать теги полей в спецификации.
Режимы движения данных
Поток данных через БД
- Очевидно самое простое решение. Но даже при таком подходе следует учесть возможность того, что часть кода читающая и пишущая код мог разойтись по версиям.
- Так же не стоит забывать про rolling update. Когда к одной БД может получать доступ как новый так и старый код.
Поток данных через сервисы: REST и RPC
REST, RESTful и SOAP
- REST - подход к проектированию API где за основу взят протокол HTTP с его глаголами, сроками жизни кэша и, например механизмами авторизации.
- RESTful эпитет применяемый к API если оно реализовано на базе REST.
- SOAP в отличии от REST хоть и базируется на HTTP но старается абстрагироваться от его возможностей.
- Логика API описывается в XML и определяется с помощью основанного на XML языка, именуемого языком описания веб-сервисов (web services description language, WSDL).
- WSDL обычно позволяет генерировать код но без такой генерации использовать его крайне сложно.
- Логика API описывается в XML и определяется с помощью основанного на XML языка, именуемого языком описания веб-сервисов (web services description language, WSDL).
RPC
Основная идея модели RPC состоит в том, что выполнение запроса к удаленному сетевому сервису должно выглядеть так же, как и вызов функции или метода на обычном языке программирования, в пределах одного процесса (эта абстракция называется независимостью от расположения (location transparency)).
Проблемы RPC:
- Сама природа семьи накладывает массу ограничений на способ вызова.
- Падение сети.
- Скорость обработки.
- Невозможность в общем случае понять дошёл ли запрос.
- Так же к минусам можно отнести невозможность передать указатель на объект. Любая передача объекта обязательно будет сопровождаться его стерилизацией.
- Приведение типов между разными языками программирования может вызвать сложности.
Поток данных передачи сообщений
- В разделе о брокерах сообщений рассказывается история вопроса и основные термины.
- Consumer, producer, topic, queue и так далее.
- Акторная модель разработки предполагает обмен сообщениями, через асинхронную очередь даже в случае одного экземпляра сервиса. Сама сущность очереди может быть инкапсулирована в сервис.
II. Распределенные данные
Существует несколько основных мотивов распределения данных по нескольким машинам:
- Масштабируемость. Если объем данных, нагрузка по чтению или записи перерастают возможности одной машины, то можно распределить эту нагрузку на несколько компьютеров.
- Отказоустойчивость/высокая доступность. Если приложение должно продолжать работать даже в случае сбоя одной из машин (или нескольких машин, или сети, или даже всего ЦОДа), то можно использовать избыточные компьютеры. При отказе одного из них выполнение задач делигируется другому.
- Задержка. При наличии пользователей по всему миру необходимы серверы в разных точках земного шара, чтобы каждый пользователь обслуживался ЦОДом, географически расположенным максимально близко от него. При этом пользователям не нужно будет ждать, пока сетевые пакеты обойдут половину земного шара.
Если цель масштабирования это всего лишь обеспечение большей производительности то можно рассмотреть следующие виды архитектуры:
- Shared-memory architecture (архитектура с разделяемой памятью) - по сути классический сервер который можно до какого-то предела растить вертикально. Из очевидных минусов - привязка к одной географической точке.
- Shared-disk architecture (архитектура с разделяемым диском) - группа сервера по высокоскоростной сети подключается к единому массиву дисков.
Архитектуры без разделения ресурсов. Напротив, архитектуры без разделения ресурсов (shared-nothing architectures), известные под названием горизонтального масштабирования (horizontal scaling, scaling out).
- Репликация (replication) - подход при котором копии одних и тех же данных хранятся на различных узлах с целью обеспечения избыточности.
- Секционирование (partitions) - подход разбиения большой БД на отдельные кусочки секции. Оба похода часто используются совместно.
5. Репликация
Допущение по тексту этой главы в том, что набор данных с которым мы оперируем достаточно мал для того чтобы влезть на одну машину. Существуют три основных подхда к репликации:
- Single-leader
- Multi-leader
- Leaderless
5.1 Ведущие и ведомые узлы
- Узлы делятся на ведущие и ведомые (master/slave). Запись разрешается только в мастер откуда через специальный лог изменения раскатываются на ведомые узлы.
- Важным фактором работы системы является синхронно или асинхронно выполняется репликация.
- Репликация может быть настроена в одном кластере не однородно. То есть например межу ведущим узлом и первым ведомым она синхронна, тогда как репликация на второй ведомый уже асинхронна.
- Делать все ведомые узлы синхронными не разумно.
- Существует подход (semi-synchronous) при котором при возникновении проблем с единственной синхронной репликой синхронный режим переключается на другой узел.
- Это гарантирует наличие как минимум двух машин с актуальным набором данных.